

In previous articles, I have written about container images and runtimes. In this article, I look at how containers are made possible by a foundation of some special Linux technologies, including namespaces and control groups.
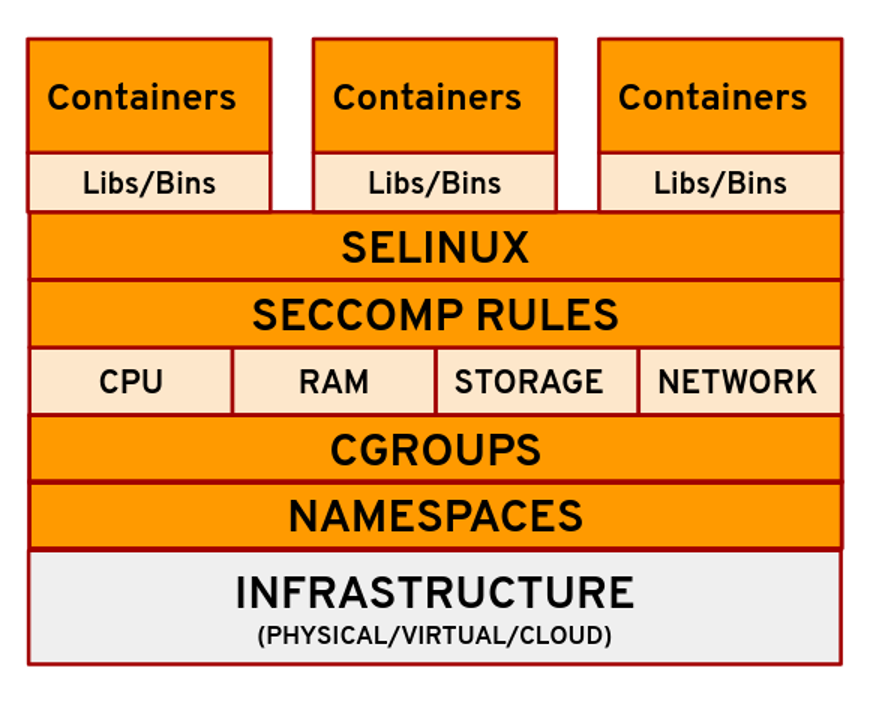
Figure 1: Linux technologies that contribute to containers
Linux technologies make up the foundations of building and running a container process on your system. Technologies include:
- Namespaces
- Control groups (cgroups)
- Seccomp
- SELinux
Namespaces
Namespaces provide a layer of isolation for the containers by giving the container a view of what appears to be its own Linux filesystem. This limits what a process can see and therefore restricts the resources available to it.
There are several namespaces in the Linux kernel that are used by Docker or Podman and others while creating a container:
$ docker container run alpine ping 8.8.8.8
$ sudo lsns -p 29413
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 299 1 root /usr/lib/systemd/systemd --
switched...
4026533105 mnt 1 29413 root ping 8.8.8.8
4026533106 uts 1 29413 root ping 8.8.8.8
4026533105 ipc 1 29413 root ping 8.8.8.8
[...]User
The user namespace isolates users and groups within a container. This is done by allowing containers to have a different view of UID and GID ranges compared to the host system. The user namespace enables the software to run inside the container as the root user. If an intruder attacks the container and then escapes to the host machine, they're confined to only a non-root identity.
Mnt
The mnt namespace allows the containers to have their own view of the system's file system hierarchy. You can find the mount points for each container process in the /proc/<PID>/mounts location in your Linux system.
UTS
The Unix Timesharing System (UTS) namespace allows containers to have a unique hostname and domain name. When you run a container, a random ID is used as the hostname even when using the — name tag. You can use the unshare command to get an idea of how this works.
$ docker container run -it --name nived alpine sh
/ # hostname
9c9a5edabdd6
/ #
$ sudo unshare -u sh
# hostname isolated.hostname
# hostname
# exit
$ hostname
homelab.redhat.comIPC
The Inter-Process Communication (IPC) namespace allows different container processes to communicate by accessing a shared range of memory or using a shared message queue.
# ipcmk -M 10M
Shared memory id: 0
# ipcmk -M 20M
Shared memory id: 1
# ipcs
---- Message Queues ----
key msqid owner perms used-bytes messages
---- Shared Memory Segments
key shmid owner perms bytes nattch status
0xd1df416a 0 root 644 10485760 0
0xbd487a9d 1 root 644 20971520 0
[...]PID
The Process ID (PID) namespace ensures that the processes running inside a container are isolated from the external world. When you run a ps command inside a container, you only see the processes running inside the container and not on the host machine because of this namespace.
Net
The network namespace allows the container to have its own view of network interface, IP addresses, routing tables, port numbers, and so on. How does a container able to communicate to the external world? All containers you create get attached to a special virtual network interface for communication.
Control groups (cgroups)
Cgroups are fundamental blocks of making a container. A cgroup allocates and limits resources such as CPU, memory, network I/O that are used by containers. The container engine automatically creates a cgroup filesystem of each type, and sets values for each container when the container is run.
SECCOMP
Seccomp basically stands for secure computing. It is a Linux feature used to restrict the set of system calls that an application is allowed to make. The default seccomp profile for Docker, for example, disables around 44 syscalls (over 300 are available).
The idea here is to provide containers access to only those resources which the container might need. For example, if you don't need the container to change the clock time on your host machine, you probably have no use for the clock_adjtime and clock_settime syscalls, and it makes sense to block them out. Similarly, you don't want the containers to change the kernel modules, so there is no need for them to make create_module, delete_module syscalls.
SELinux
SELinux stands for security-enhanced Linux. If you are running a Red Hat distribution on your hosts, then SELinux is enabled by default. SELinux lets you limit an application to have access only to its own files and prevent any other processes from accessing them. So, if an application is compromised, it would limit the number of files that it can affect or control. It does this by setting up contexts for files and processes and by defining policies that would enforce what a process can see and make changes to.
SELinux policies for containers are defined by the container-selinux package. By default, containers are run with the container_t label and are allowed to read (r) and execute (x) under the /usr directory and read most content from the /etc directory. The label container_var_lib_t is common for files relating to containers.
Wrap up
Containers are a critical part of today's IT infrastructure and a pretty interesting technology, too. Even if your role doesn't involve containerization directly, understanding a few fundamental container concepts and approaches gives you an appreciation for how they can help your organization. The fact that containers are built on open source Linux technologies makes them even better!
This article is based on a techbeatly article and has been adapted with permission.








Comments are closed.